
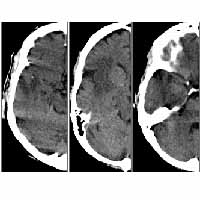
Existing "content-based" image retrieval systems depend on general visual properties such as color and texture to classify diverse, two-dimensional (2D) images. These general visual cues, however, often fail to be effective discriminators for image sets taken within a single domain, where images have subtle, domain-specific differences. Furthermore, these visual properties are not necessarily the true content of an image, nor do they have a proven correspondence to image semantics, i.e. the meaning of an image. Databases composed of (3D volumetric or 2D) images and their collateral information in a particular medical domain form simple, semantically well-defined training sets, where the semantics of each image is the pathology indicated by that image (for example, normal, hemorrhage, stroke or tumor in neuroimages, or normal v. cancer in microscopic images). The goal of our research is to:
- construct creative statistical image features such that the image semantics are captured with high probabilities;
- select the most discriminative (across different pathology classes) feature subset from all possible potential indexing features computed from a multimedia, multi-dimensional database;
- use the most discriminative feature-subset as the front-end index to find (for image classification or retrieval) medically similar cases in a large image database to aid diagnosis, surgical planning, patient treatment, outcome evaluation and medical education.
Our approach is a principled method firmly rooted in Bayes decision theory. Techniques in memory-based learning, feature selection and statistical regression are adopted in our system to achieve classification-driven, semantic based image analysis, indexing and retrieval.